
-
 Saefulloh Maslul
Saefulloh Maslul
- 22 Sep, 2024
Pengenalan Machine Learning dan Bagaimana Cara Kerjanya
Apa itu machine learning? Namun sebelum kita membahas lebih jauh, mari kita pahami terlebih dahulu apa itu model.

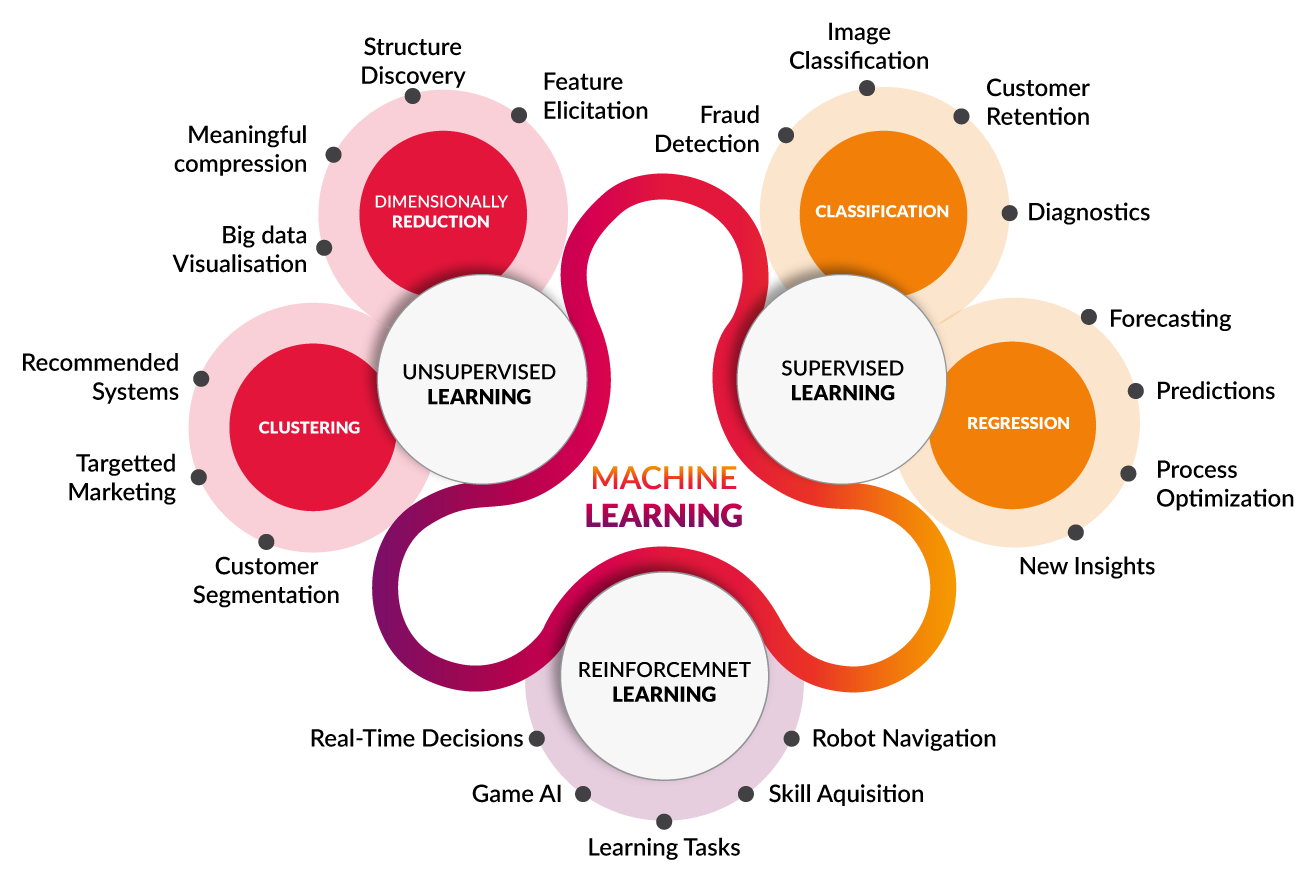
Machine learning adalah salah satu cabang dari kecerdasan buatan (Artificial Intelligence) yang memungkinkan sistem komputer untuk belajar dari data, mengidentifikasi pola, dan membuat keputusan dengan sedikit atau tanpa campur tangan manusia.
Machine learning dibagi menjadi beberapa jenis berdasarkan bagaimana model dilatih dan jenis data yang digunakan.
Supervised learning adalah jenis Machine learning di mana model dilatih menggunakan data yang sudah dilabeli. Artinya, setiap input data disertai dengan jawaban output yang benar. Algoritma akan belajar untuk memprediksi output berdasarkan input dan label yang sudah ada.
Contoh kasus:
Algoritma yang bisa digunakan:
Berikut adalah contoh implementasi untuk klasifikasi email spam atau bukan:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Data training
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
# Training model
model.fit(X_train, y_train)
# Prediksi data test
y_pred = model.predict(X_test)
# Evaluasi model
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
Keunggulan
Kekurangan
Berbeda dengan supervised, Unsupervised learning tidak memerlukan data yang sudah dilabeli. Algoritma unsupervised akan belajar dari data tanpa disertai label, dan bertujuan untuk menemukan pola atau struktur yang tersembunyi dalam data.
Contoh kasus:
Algoritma yang populer:
Berikut adalah contoh implementasi untuk pengelompokan data menggunakan K-Means:
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# Standarisasi data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Inisialisasi model K-Means
kmeans = KMeans(n_clusters=3, random_state=42)
# Training model
kmeans.fit(X_scaled)
y_kmeans = kmeans.predict(X)
# Visualisasi hasil clustering
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='x')
plt.title('K-Means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
Keunggulan
Kekurangan
Semi-supervised learning adalah kombinasi dari supervised dan unsupervised learning. Algoritma akan menggunakan data yang sudah dilabeli untuk membantu mengelompokan atau membuat prediksi data yang tidak dilabeli.
Contoh kasus:
Algoritma yang bisa digunakan:
Keunggulan
Kekurangan
Reinforcement learning adalah jenis Machine learning di mana model belajar melalui interaksi dengan lingkungan. Model akan belajar dari reward atau penalty yang diberikan oleh lingkungan berdasarkan tindakan yang diambil.
Contoh kasus:
Algoritma yang populer:
Keunggulan
Kekurangan
Self-supervised learning adalah jenis Machine learning di mana model belajar dari data tanpa memerlukan label eksternal. Model akan membuat label sendiri dari data yang ada. Algoritma ini masih dalam pengembangan dan menjadi tren baru dalam Machine learning.
Contoh kasus:
Algoritma yang bisa digunakan:
Keunggulan
Kekurangan
Machine learning memiliki berbagai jenis yang dapat digunakan tergantung pada tipe data dan tujuan yang ingin dicapai. Dengan memahami jenis-jenis Machine learning, kita dapat memilih algoritma yang paling sesuai dengan kasus yang dihadapi.

Apa itu machine learning? Namun sebelum kita membahas lebih jauh, mari kita pahami terlebih dahulu apa itu model.

Property dan decorator adalah fitur powerful di Python yang membuat kode lebih elegan, aman, dan mudah dirawat, terutama dalam paradigma Object-Oriented Programming (OOP).

Static method dan class method adalah dua jenis method khusus di Python yang sering digunakan dalam OOP.

Method overriding dan overloading adalah dua teknik penting dalam OOP untuk membuat method lebih fleksibel dan sesuai kebutuhan.