Apa itu regresi?
Apa itu klasifikasi?
Sebelum kita masuk ke definisi, mari kita pahami beberapa tipe machine learning.
Machine learning terdiri dari beberapa tipe, yaitu: supervised learning, unsupervised learning, dan reinforcement learning.
Dan supervised learning terdiri dari dua tipe, yaitu regresi dan klasifikasi.
Regresi
Regresi adalah tipe supervised learning yang digunakan untuk memprediksi nilai kontinu.
Contoh:
- Memprediksi harga rumah
- Memprediksi harga saham
- Memprediksi suhu
Intinya, regresi digunakan untuk memprediksi nilai kontinu.
Klasifikasi
Klasifikasi adalah tipe supervised learning yang digunakan untuk memprediksi kelas atau label.
Contoh:
- Memprediksi apakah email spam atau bukan
- Memprediksi apakah gambar berisi kucing atau bukan
- Memprediksi apakah pasien memiliki penyakit jantung atau tidak
Intinya, klasifikasi digunakan untuk memprediksi kelas atau label. Kelas atau label disini bisa saja bernilai numerik, misalnya 0 dan 1, atau bisa juga bernilai kategorikal, misalnya spam dan bukan spam.
Tidak selalu target prediksi yang bernilai angka menggunakan regresi, klasifikasi juga bisa bernilai angka. Bedanya angka di klasifikasi merupakan label atau kelas, sedangkan angka di regresi merupakan nilai yang diprediksi.
Algoritma Regresi dan Klasifikasi
Ada banyak algoritma regresi, diantaranya:
- Simple Linear Regression
- Multiple Linear Regression
- Polynomial Regression
- Ridge Regression
- Lasso Regression
- Elastic Net Regression
Ada banyak juga algoritma klasifikasi, diantaranya:
- Logistic Regression
- K-Nearest Neighbors (KNN)
- Support Vector Machine (SVM)
- Decision Tree
- Random Forest
Simple Linear Regression
Simple Linear Regression adalah algoritma regresi yang paling sederhana. Algoritma ini digunakan untuk memprediksi nilai kontinu berdasarkan satu variabel independen.
Rumusnya:
Dimana:
- y adalah nilai yang diprediksi
- b0 adalah intercept
- b1 adalah koefisien
- x adalah variabel independen
Tujuan dari simple linear regression adalah untuk mendapatkan nilai b0 dan b1 yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error.
Contoh:
import numpy as np
from sklearn.linear_model import LinearRegression
# Data
x = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 6, 8, 10])
# Model
model = LinearRegression()
model.fit(x, y)
# Prediksi
x_pred = np.array([6]).reshape(-1, 1)
y_pred = model.predict(x_pred)
print(y_pred)
Multiple Linear Regression
Multiple Linear Regression adalah algoritma regresi yang digunakan untuk memprediksi nilai kontinu berdasarkan beberapa variabel independen.
Rumusnya:
y = b0 + b1 * x1 + b2 * x2 + ... + bn * xn
Dimana:
- y adalah nilai yang diprediksi
- b0 adalah intercept
- b1, b2, …, bn adalah koefisien
- x1, x2, …, xn adalah variabel independen
Tujuan dari multiple linear regression adalah untuk mendapatkan nilai b0, b1, b2, …, bn yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error.
Contoh:
import numpy as np
from sklearn.linear_model import LinearRegression
# Data
x = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y = np.array([3, 5, 7, 9, 11])
# Model
model = LinearRegression()
model.fit(x, y)
# Prediksi
x_pred = np.array([[6, 7]])
y_pred = model.predict(x_pred)
print(y_pred)
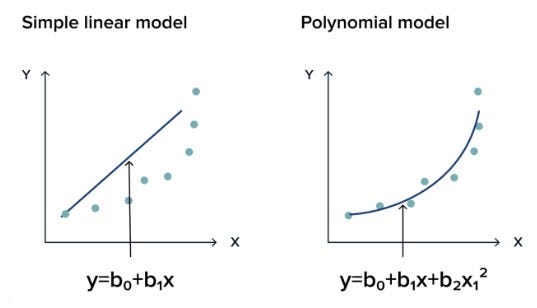
Polynomial Regression
Polynomial Regression adalah algoritma regresi yang digunakan untuk memprediksi nilai kontinu berdasarkan variabel independen yang memiliki hubungan non-linear.
Rumusnya:
y = b0 + b1 * x + b2 * x^2 + ... + bn * x^n
Dimana:
- y adalah nilai yang diprediksi
- b0 adalah intercept
- b1, b2, …, bn adalah koefisien
- x adalah variabel independen
- n adalah derajat polinomial
Tujuan dari polynomial regression adalah untuk mendapatkan nilai b0, b1, b2, …, bn yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error.
Bentuk dari polynomial regression bisa berbeda-beda tergantung dari derajat polinomial yang digunakan. Contohnya bisa berbentuk garis lurus, parabola, atau kurva lainnya.
Contoh:
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
# Data
x = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 6, 8, 10])
# Polynomial Features
poly = PolynomialFeatures(degree=2)
x_poly = poly.fit_transform(x)
# Model
model = LinearRegression()
model.fit(x_poly, y)
# Prediksi
x_pred = np.array([6]).reshape(-1, 1)
x_pred_poly = poly.fit_transform(x_pred)
y_pred = model.predict(x_pred_poly)
print(y_pred)
Ridge Regression
Ridge Regression adalah algoritma regresi yang digunakan untuk mengatasi overfitting pada multiple linear regression.
Rumusnya:
y = b0 + b1 * x1 + b2 * x2 + ... + bn * xn + alpha * (b1^2 + b2^2 + ... + bn^2)
Dimana:
- y adalah nilai yang diprediksi
- b0 adalah intercept
- b1, b2, …, bn adalah koefisien
- x1, x2, …, xn adalah variabel independen
- alpha adalah hyperparameter
Tujuan dari ridge regression adalah untuk mendapatkan nilai b0, b1, b2, …, bn yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error dan mengurangi overfitting.
Perbedaan ridge regression dengan multiple linear regression adalah adanya tambahan alpha * (b1^2 + b2^2 + … + bn^2) pada rumusnya.
Hal ini karena ridge regression menambahkan regularisasi L2 untuk mengurangi overfitting. Regularisasi L2 adalah penalti yang diberikan pada koefisien agar tidak terlalu besar.
Contoh:
import numpy as np
from sklearn.linear_model import Ridge
# Data
x = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y = np.array([3, 5, 7, 9, 11])
# Model
model = Ridge(alpha=1)
model.fit(x, y)
# Prediksi
x_pred = np.array([[6, 7]])
y_pred = model.predict(x_pred)
print(y_pred)
Lasso Regression
Lasso Regression adalah algoritma regresi yang digunakan untuk mengatasi overfitting pada multiple linear regression. Perbedaannya dengan ridge regression adalah menggunakan regularisasi L1.
Rumusnya:
y = b0 + b1 * x1 + b2 * x2 + ... + bn * xn + alpha * (|b1| + |b2| + ... + |bn|)
Dimana:
- y adalah nilai yang diprediksi
- b0 adalah intercept
- b1, b2, …, bn adalah koefisien
- x1, x2, …, xn adalah variabel independen
- alpha adalah hyperparameter
Tujuan dari lasso regression adalah untuk mendapatkan nilai b0, b1, b2, …, bn yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error dan mengurangi overfitting.
Contoh:
import numpy as np
from sklearn.linear_model import Lasso
# Data
x = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y = np.array([3, 5, 7, 9, 11])
# Model
model = Lasso(alpha=1)
model.fit(x, y)
# Prediksi
x_pred = np.array([[6, 7]])
y_pred = model.predict(x_pred)
print(y_pred)
Elastic Net Regression
Elastic Net Regression adalah algoritma regresi yang menggabungkan ridge regression dan lasso regression.
Rumusnya:
y = b0 + b1 * x1 + b2 * x2 + ... + bn * xn + alpha * ((1 - l1_ratio) * (b1^2 + b2^2 + ... + bn^2) + l1_ratio * (|b1| + |b2| + ... + |bn|))
Dimana:
- y adalah nilai yang diprediksi
- b0 adalah intercept
- b1, b2, …, bn adalah koefisien
- x1, x2, …, xn adalah variabel independen
- alpha adalah hyperparameter
- l1_ratio adalah hyperparameter
Tujuan dari elastic net regression adalah untuk mendapatkan nilai b0, b1, b2, …, bn yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error dan mengurangi overfitting.
Contoh:
import numpy as np
from sklearn.linear_model import ElasticNet
# Data
x = np.array([[1, 2], [2, 3], [3, 4], [4, 5], [5, 6]])
y = np.array([3, 5, 7, 9, 11])
# Model
model = ElasticNet(alpha=1, l1_ratio=0.5)
model.fit(x, y)
# Prediksi
x_pred = np.array([[6, 7]])
y_pred = model.predict(x_pred)
print(y_pred)
Logistic Regression

Logistic Regression adalah algoritma klasifikasi yang digunakan untuk memprediksi kelas atau label berdasarkan variabel independen.
Rumusnya:
p = 1 / (1 + e^(-(b0 + b1 * x1 + b2 * x2 + ... + bn * xn)))
Dimana:
- p adalah probabilitas
- e adalah bilangan Euler
- b0 adalah intercept
- b1, b2, …, bn adalah koefisien
Tujuan dari logistic regression adalah untuk mendapatkan koefisien yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error.
Contoh:
import numpy as np
from sklearn.linear_model import LogisticRegression
# Data prediksi email spam atau bukan yang terdiri dari message dan label
data = [
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
]
# Data
x = np.array([row[0] for row in data])
y = np.array([row[1] for row in data])
# Model
model = LogisticRegression()
model.fit(x, y)
# Prediksi
x_pred = np.array(['Hello, how are you?'])
y_pred = model.predict(x_pred)
print(y_pred)
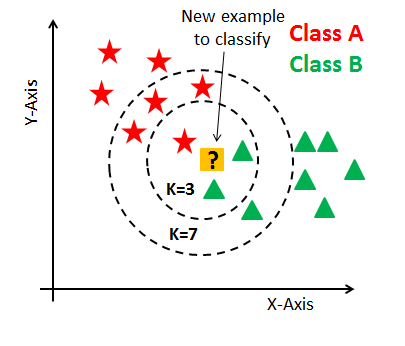
K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) adalah algoritma klasifikasi yang digunakan untuk memprediksi kelas atau label berdasarkan variabel independen.
Rumusnya:
y = mode(y1, y2, ..., yk)
Dimana:
- y adalah kelas atau label yang diprediksi
- y1, y2, …, yk adalah kelas atau label dari k tetangga terdekat
- k adalah jumlah tetangga terdekat
Tujuan dari KNN adalah untuk mendapatkan kelas atau label yang paling sering muncul dari k tetangga terdekat.
Contoh:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# Data
data = [
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
]
X = np.array([row[0] for row in data])
y = np.array([row[1] for row in data])
# Model
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X, y)
# Prediksi
X_pred = np.array(['Hello, how are you?'])
y_pred = model.predict(X_pred)
print(y_pred)
Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah algoritma klasifikasi yang digunakan untuk memprediksi kelas atau label berdasarkan variabel independen.
Rumusnya:
y = sign(b0 + b1 * x1 + b2 * x2 + ... + bn * xn)
Dimana:
- y adalah kelas atau label yang diprediksi
- b0 adalah intercept
- b1, b2, …, bn adalah koefisien
Tujuan dari SVM adalah untuk mendapatkan koefisien yang terbaik sehingga prediksi yang dihasilkan seminimal mungkin error dan memaksimalkan margin.
Contoh:
import numpy as np
from sklearn.svm import SVC
# Data
data = [
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
]
X = np.array([row[0] for row in data])
y = np.array([row[1] for row in data])
# Model
model = SVC()
model.fit(X, y)
# Prediksi
X_pred = np.array(['Hello, how are you?'])
y_pred = model.predict(X_pred)
print(y_pred)
Decision Tree
Decision Tree adalah algoritma klasifikasi yang digunakan untuk memprediksi kelas atau label berdasarkan variabel independen.
Rumusnya:
Dimana:
- y adalah kelas atau label yang diprediksi
- x1, x2, …, xn adalah variabel independen
- f adalah fungsi yang menghasilkan kelas atau label
Tujuan dari decision tree adalah untuk membuat pohon keputusan yang membagi data menjadi beberapa bagian berdasarkan variabel independen.
Contoh:
import numpy as np
from sklearn.tree import DecisionTreeClassifier
# Data
data = [
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
]
X = np.array([row[0] for row in data])
y = np.array([row[1] for row in data])
# Model
model = DecisionTreeClassifier()
model.fit(X, y)
# Prediksi
X_pred = np.array(['Hello, how are you?'])
y_pred = model.predict(X_pred)
print(y_pred)
Random Forest
Random Forest adalah algoritma klasifikasi yang digunakan untuk memprediksi kelas atau label berdasarkan variabel independen.
Rumusnya:
y = mode(f1(x1, x2, ..., xn), f2(x1, x2, ..., xn), ..., fk(x1, x2, ..., xn))
Dimana:
- y adalah kelas atau label yang diprediksi
- x1, x2, …, xn adalah variabel independen
- f1, f2, …, fk adalah decision tree
Tujuan dari random forest adalah untuk membuat beberapa decision tree dan mengambil hasil prediksi yang paling sering muncul.
Contoh:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# Data
data = [
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
['Hello, how are you?', 0],
['Win a free trip!', 1],
['Get a discount!', 1],
]
X = np.array([row[0] for row in data])
y = np.array([row[1] for row in data])
# Model
model = RandomForestClassifier()
model.fit(X, y)
# Prediksi
X_pred = np.array(['Hello, how are you?'])
y_pred = model.predict(X_pred)
print(y_pred)
Perbandingan Algoritma Regresi
| Algoritma |
Deskripsi |
Kelebihan |
Kekurangan |
| Simple Linear Regression |
Memodelkan hubungan antara dua variabel dengan persamaan linier. |
Sederhana untuk diimplementasikan dan diinterpretasikan. |
Terbatas pada hubungan linier. |
| Multiple Linear Regression |
Memperluas regresi linier sederhana dengan menggunakan beberapa variabel independen. |
Dapat memodelkan hubungan antara banyak prediktor dan respons. |
Asumsi linearitas mungkin tidak menangkap hubungan yang kompleks. |
| Polynomial Regression |
Memodelkan hubungan non-linier antara variabel independen dan dependen dengan menambahkan istilah polinomial. |
Dapat memodelkan hubungan yang lebih kompleks dibanding regresi linier. |
Rentan terhadap overfitting dengan polinomial derajat tinggi. |
| Ridge Regression |
Menambahkan penalti (regulasi L2) untuk mengurangi kompleksitas model dan mencegah overfitting. |
Mengurangi overfitting dan mempertahankan semua fitur. |
Masih bisa menyertakan fitur yang tidak informatif. |
| Lasso Regression |
Menambahkan penalti (regulasi L1) yang dapat menghasilkan model yang lebih sederhana dengan seleksi fitur. |
Melakukan seleksi fitur otomatis dan mengurangi overfitting. |
Dapat menghilangkan fitur yang mungkin penting. |
| Elastic Net Regression |
Menggabungkan regulasi L1 (Lasso) dan L2 (Ridge) untuk menyeimbangkan antara dua penalti. |
Menyediakan model fleksibel yang menggabungkan seleksi fitur dan regulasi. |
Memerlukan penyetelan hyperparameter yang hati-hati. |
Perbandingan Algoritma Klasifikasi
| Algoritma |
Deskripsi |
Kelebihan |
Kekurangan |
| Logistic Regression |
Algoritma regresi yang digunakan untuk masalah klasifikasi biner dengan memodelkan probabilitas hasil. |
Sederhana untuk diimplementasikan dan diinterpretasikan untuk klasifikasi biner. |
Terbatas pada batasan keputusan linier. |
| K-Nearest Neighbors (KNN) |
Algoritma non-parametrik yang mengklasifikasikan data berdasarkan mayoritas dari k tetangga terdekat. |
Mudah dipahami dan diimplementasikan; tidak memerlukan pelatihan. |
Sensitif terhadap pemilihan k dan bisa lambat dengan dataset besar. |
| Support Vector Machine (SVM) |
Algoritma pembelajaran terawasi yang menemukan hyperplane optimal untuk memisahkan kelas. |
Efektif dalam ruang berdimensi tinggi dan bekerja baik dengan margin pemisahan yang jelas. |
Membutuhkan penyetelan parameter yang cermat dan bisa mahal secara komputasi. |
| Decision Tree |
Model berbasis pohon yang membagi data ke dalam cabang-cabang berdasarkan nilai fitur. |
Mudah diinterpretasikan dan divisualisasikan; menangani data kategorikal dan numerik. |
Rentan terhadap overfitting pada pohon yang dalam. |
| Random Forest |
Metode pembelajaran ensemble yang menggabungkan banyak decision tree untuk meningkatkan kinerja. |
Mengurangi overfitting dan meningkatkan akurasi dengan merata-ratakan banyak pohon. |
Lebih kompleks dan lebih sulit diinterpretasikan dibandingkan decision tree tunggal. |
Cara Memilih Algoritma
Cara memilih algoritma tergantung pada data dan masalah yang ingin diselesaikan. Namun, pada jaman sekarang, dimana komputer sudah sangat canggih, kita bisa mencoba beberapa algoritma sekaligus dan memilih yang terbaik.
Berikut adalah beberapa hal yang perlu dipertimbangkan saat memilih algoritma:
- Jumlah Data: Jika jumlah data besar, algoritma yang membutuhkan waktu komputasi yang lama mungkin tidak cocok.
- Jumlah Fitur: Jika jumlah fitur besar, algoritma yang sensitif terhadap dimensi mungkin tidak cocok.
- Interpretasi: Jika interpretasi model penting, algoritma yang mudah diinterpretasikan mungkin lebih baik.
- Performa: Jika performa model penting, algoritma yang memiliki akurasi tinggi mungkin lebih baik.
- Overfitting: Jika overfitting menjadi masalah, algoritma yang memiliki regularisasi mungkin lebih baik.
- Kemampuan: Jika kemampuan model penting, algoritma yang memiliki kemampuan yang sesuai mungkin lebih baik.
- Kemudahan: Jika kemudahan implementasi penting, algoritma yang mudah diimplementasikan mungkin lebih baik.
Kesimpulan
Regresi dan klasifikasi adalah dua tipe supervised learning yang digunakan untuk memprediksi nilai kontinu dan kelas atau label. Ada banyak algoritma regresi dan klasifikasi yang bisa digunakan tergantung pada data dan masalah yang ingin diselesaikan. Pemilihan algoritma tergantung pada jumlah data, jumlah fitur, interpretasi, performa, overfitting, kemampuan, dan kemudahan implementasi.



 Saefulloh Maslul
Saefulloh Maslul


