Apa itu Model Klasifikasi?
Model klasifikasi adalah salah satu jenis model machine learning yang digunakan untuk memprediksi kelas atau label dari data yang diberikan. Model ini mempelajari pola dari data yang diberikan dan kemudian digunakan untuk memprediksi kelas dari data baru.
Contoh:
- Prediksi apakah email adalah spam atau bukan.
- Prediksi apakah pasien memiliki penyakit tertentu atau tidak.
- Prediksi apakah pelanggan akan membeli produk tertentu atau tidak.
Metode Klasifikasi
Ada banyak metode klasifikasi yang dapat digunakan untuk membangun model klasifikasi, salah satunya adalah Decision Trees.
Decision Trees adalah model klasifikasi yang sangat populer dan mudah dipahami. Model ini bekerja dengan membagi data menjadi dua bagian berdasarkan fitur-fitur yang ada. Proses ini dilakukan secara rekursif hingga mencapai kondisi berhenti.
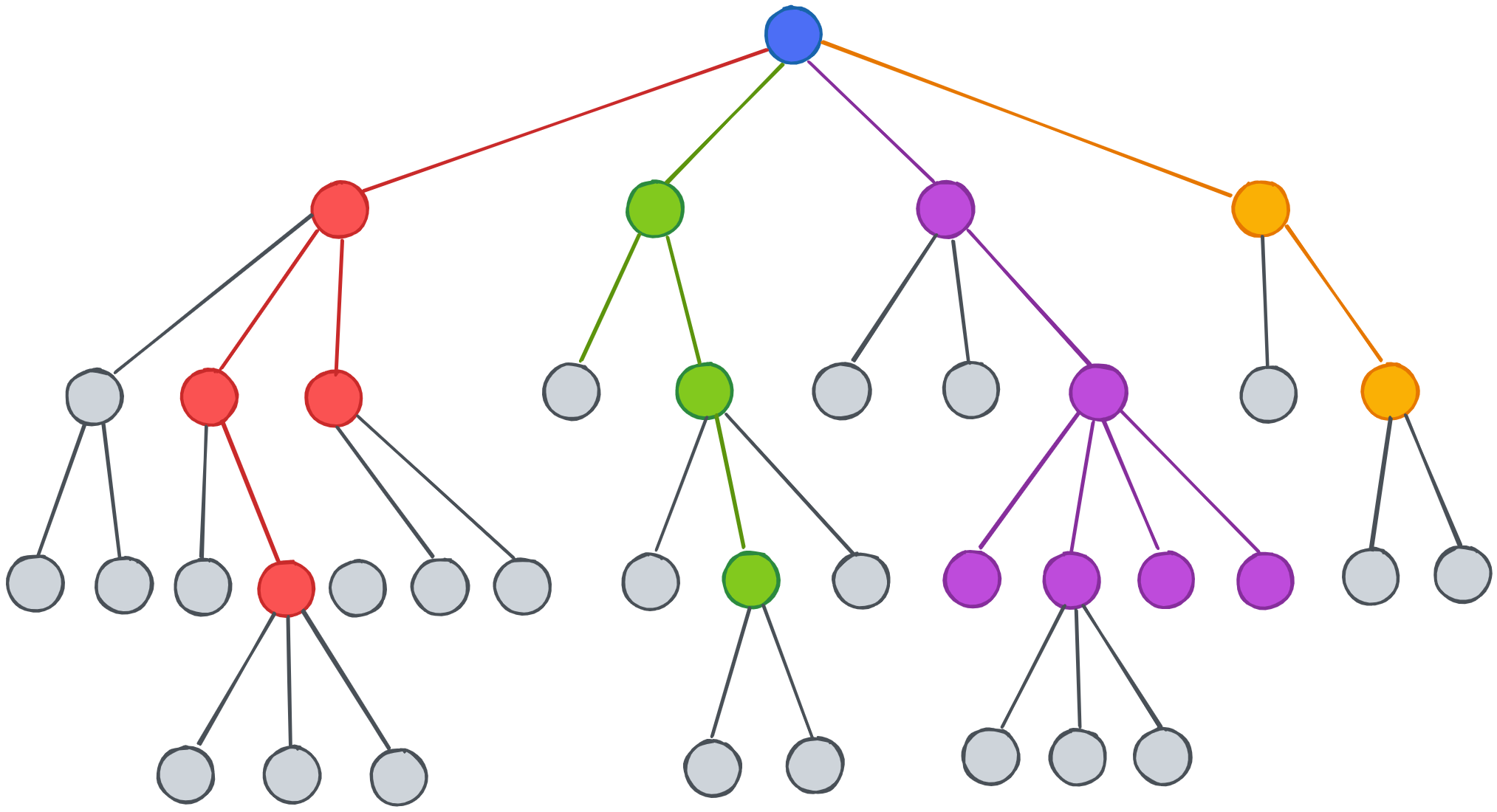
Studi Kasus
Kita akan membangun model klasifikasi menggunakan Decision Trees untuk memprediksi apakah seorang pasien memiliki penyakit jantung atau tidak berdasarkan fitur-fitur tertentu.
Dataset yang akan kita gunakan adalah Heart Disease UCI Dataset yang berisi data kesehatan dari 303 pasien. Dataset ini memiliki 14 kolom dengan rincian sebagai berikut:
| Feature |
Deskripsi |
age |
Usia pasien dalam tahun |
sex |
Jenis kelamin (1 = laki-laki, 0 = perempuan) |
cp |
Tipe nyeri dada (1 = typical angina, 2 = atypical angina, 3 = non-anginal pain, 4 = asymptomatic) |
trestbps |
Tekanan darah saat istirahat |
chol |
Kolesterol dalam mg/dl |
fbs |
Gula darah puasa > 120 mg/dl (1 = ya, 0 = tidak) |
restecg |
Hasil elektrokardiogram saat istirahat (0 = normal, 1 = abnormalitas gelombang ST-T, 2 = hipertrofi ventrikel kiri) |
thalach |
Detak jantung maksimum |
exang |
Angina akibat olahraga (1 = ya, 0 = tidak) |
oldpeak |
Depresi ST akibat olahraga |
slope |
Slope segmen ST latihan (1 = upsloping, 2 = flat, 3 = downsloping) |
ca |
Jumlah pembuluh darah utama (0-3) yang terlihat melalui flourosopy |
thal |
Thalassemia (3 = normal, 6 = cacat tetap, 7 = cacat reversibel) |
target |
Penyakit jantung (0 = tidak ada penyempitan arteri >50%, 1 = terdapat penyempitan arteri >50%) |
Dataset ini dapat diunduh dari UCI Machine Learning Repository.
Membangun Model Decision Trees
Berikut adalah langkah-langkah untuk membangun model Decision Trees menggunakan Python:
Import Library
Kita akan menggunakan library pandas untuk memuat dan memanipulasi data, sklearn untuk membangun model Decision Trees, dan accuracy_score untuk mengevaluasi model.
Model Decision Trees yang akan kita gunakan adalah DecisionTreeClassifier diimport dari sklearn.tree.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
Load Dataset
Dataset yang akan kita gunakan adalah Heart Disease UCI Dataset. Kita dapat memuat dataset ini menggunakan pd.read_csv dari URL dataset.
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/processed.cleveland.data'
columns = [
'age',
'sex',
'cp',
'trestbps',
'chol',
'fbs',
'restecg',
'thalach',
'exang',
'oldpeak',
'slope',
'ca',
'thal',
'target'
]
data = pd.read_csv(url, names=columns)
Preprocessing Data
-
Menghapus data yang hilang; ini kita lakukan agar model dapat bekerja dengan baik karena model tidak dapat menangani data yang hilang.
-
Mengubah tipe data kolom ca dan thal menjadi float. Hal ini dilakukan karena kolom tersebut seharusnya bertipe float, tetapi di dataset ini bertipe object.
data['ca'] = pd.to_numeric(data['ca'], errors='coerce')
data['thal'] = pd.to_numeric(data['thal'], errors='coerce')
data['ca'] = data['ca'].astype(float)
data['thal'] = data['thal'].astype(float)
Seleksi Fitur yang Tidak Relevan
Untuk menyeleksi fitur yang tidak relevan, kita dapat menggunakan metode korelasi. Fitur yang memiliki korelasi rendah dengan target dapat dihapus.
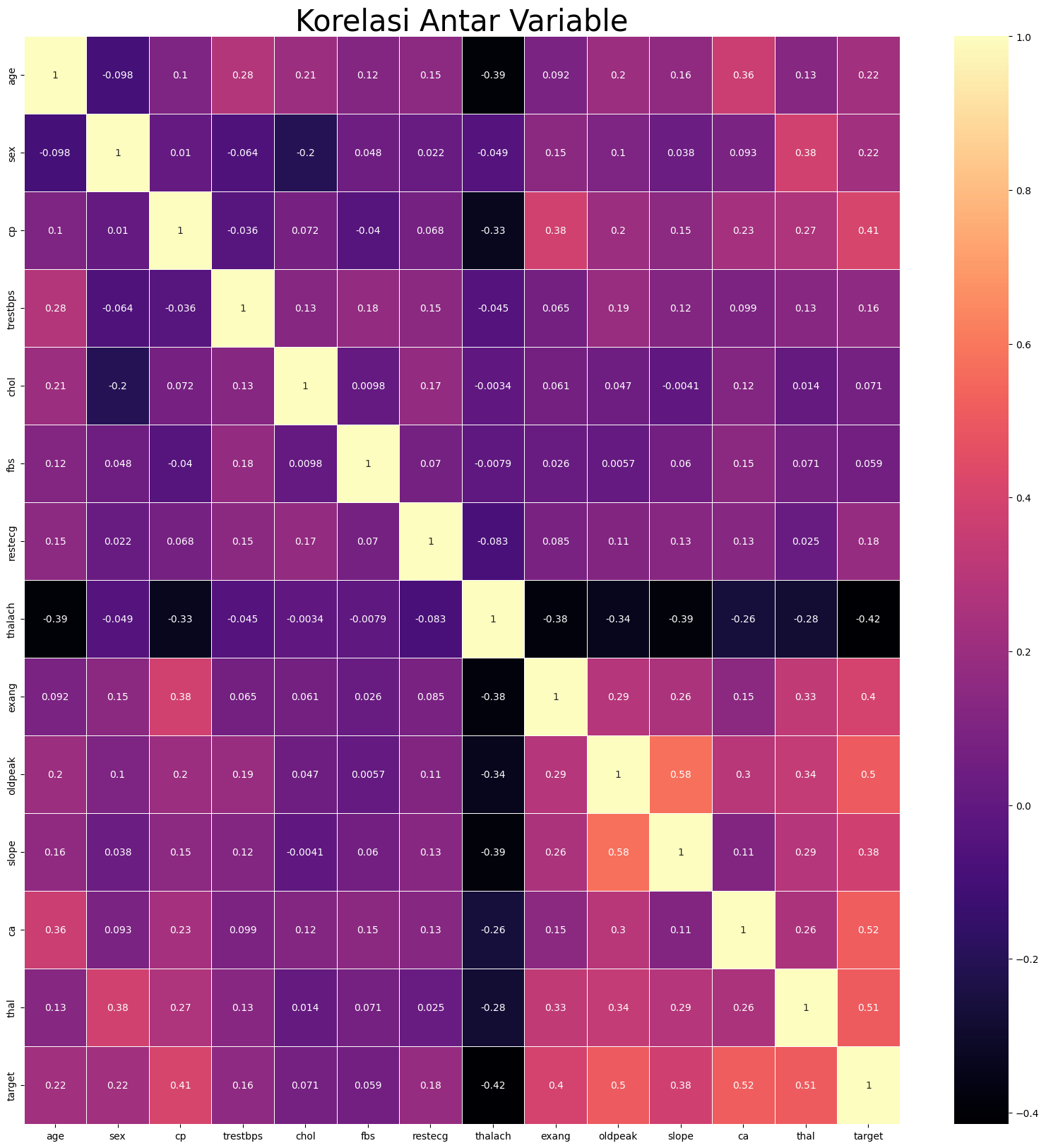
corr_threshold = 0.3
corr = data.corr()
corr_target = abs(corr['target'])
irrelevant_features = corr_target[corr_target < corr_threshold].index
data = data.drop(irrelevant_features, axis=1)
Pada kode di atas, kita menentukan threshold korelasi sebesar 0.3. Fitur yang memiliki korelasi kurang dari 0.3 dengan target akan dihapus.
Split Data
Kita akan membagi data menjadi data latih dan data uji menggunakan train_test_split. Test size yang digunakan adalah 0.2, yang berarti data uji akan memiliki 20% dari total data.
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Build Model
Build model Decision Trees menggunakan DecisionTreeClassifier dan fit model menggunakan data latih.
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
Predict Data
Prediksi data uji menggunakan model yang telah dibangun.
y_pred = model.predict(X_test)
Evaluate Model
Evaluasi model berfungsi untuk mengetahui seberapa baik model yang telah dibangun. Pada kasus ini, kita akan menggunakan metrik akurasi.
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
Accuracy: 0.4426229508196721
Apabila kita lihat, akurasi model yang dihasilkan masih rendah. Oleh karena itu kita akan lakukan tuning hyperparameter untuk meningkatkan akurasi model.
Hyperparameter Tuning
Hyperparameter tuning adalah proses mencari kombinasi hyperparameter yang optimal untuk meningkatkan performa model. Pada Decision Trees, terdapat beberapa hyperparameter yang dapat diatur, seperti max_depth, min_samples_split, dan min_samples_leaf.
Berikut adalah langkah-langkah untuk melakukan hyperparameter tuning pada Decision Trees:
Import Library GridSearchCV
Library GridSearchCV digunakan untuk mencari kombinasi hyperparameter yang optimal menggunakan teknik grid search. Grid search bekerja dengan mencoba semua kombinasi hyperparameter yang mungkin dari parameter yang ditentukan. Library ini diimport dari sklearn.model_selection yang merupakan bagian dari scikit-learn framework untuk machine learning.
GridSearchCV akan melakukan validasi silang (cross validation) pada setiap kombinasi parameter untuk menemukan model terbaik. Ini membantu menghindari overfitting dan memastikan model yang dihasilkan lebih robust.
from sklearn.model_selection import GridSearchCV
Define Hyperparameters
Kita akan mendefinisikan hyperparameter yang akan diuji menggunakan grid search. Hyperparameter yang akan diuji adalah max_depth, min_samples_split, dan min_samples_leaf.
param_grid = {
'max_depth': [3, 5, 7, 9],
'min_samples_split': [2, 4, 6, 8],
'min_samples_leaf': [1, 2, 3, 4],
}
Keterangan:
max_depth: Maksimum kedalaman pohon. Semakin dalam pohon, semakin kompleks modelnya.min_samples_split: Jumlah sampel minimum yang diperlukan untuk membagi node. Semakin tinggi nilainya, semakin sedikit node yang akan dibagi.min_samples_leaf: Jumlah sampel minimum yang diperlukan di setiap leaf node. Semakin tinggi nilainya, semakin sedikit leaf node yang akan dihasilkan.
Grid Search
Lakukan grid search untuk mencari kombinasi hyperparameter yang optimal.
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
Best Parameters
Mencari kombinasi hyperparameter terbaik yang dihasilkan oleh grid search. Kombinasi hyperparameter terbaik ini akan digunakan untuk membangun model Decision Trees yang optimal.
print(f'Best Parameters: {grid_search.best_params_}')
Best Parameters: {'max_depth': 5, 'min_samples_leaf': 3, 'min_samples_split': 2}
Predict Data
Prediksi data uji menggunakan model yang telah dibangun dengan kombinasi hyperparameter terbaik.
y_pred = grid_search.predict(X_test)
Evaluate Model
Evaluasi model menggunakan metrik akurasi. Akurasi model yang dihasilkan setelah hyperparameter tuning akan lebih baik daripada sebelumnya.
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
Accuracy: 0.5409836065573771
Dari hasil di atas, kita dapat melihat bahwa akurasi model yang dihasilkan setelah hyperparameter tuning lebih baik daripada sebelumnya.
Untuk meningkatkan lagi akurasi model, kita dapat mencoba hyperparameter tuning dengan kombinasi hyperparameter yang berbeda atau menggunakan metode klasifikasi lainnya seperti Random Forest, Gradient Boosting, Support Vector Machine atau Logistic Regression.
Kesimpulan
Dalam tutorial ini, kita telah mempelajari cara membangun model klasifikasi menggunakan Decision Trees untuk memprediksi apakah seorang pasien memiliki penyakit jantung atau tidak berdasarkan fitur-fitur tertentu. Kita juga telah mempelajari tentang hyperparameter tuning untuk meningkatkan akurasi model.



 Saefulloh Maslul
Saefulloh Maslul


